
AI Doesn't Just Think Longer—It Thinks Socially
What if the secret to AI reasoning isn’t thinking harder—but thinking together?
New research from the University of Chicago and Google reveals something surprising about how advanced reasoning models like DeepSeek-R1 actually work. These models don’t just run more computation. They simulate something that looks remarkably like a group discussion, complete with questions, disagreements, and perspective shifts.
For anyone building AI systems that need to evaluate content from multiple viewpoints, this paper is essential reading.
TL;DR
Reasoning models improve performance by generating what researchers call a “society of thought”—internal simulations of multi-agent interactions where diverse perspectives debate and synthesize ideas. When researchers amplified a single conversational feature in DeepSeek-R1, accuracy on reasoning tasks nearly doubled, jumping from 27.1% to 54.8%.
If you only take one thing away: The best AI reasoning doesn’t come from deeper individual analysis—it comes from structured diversity and internal debate.
The Research
Paper: Reasoning Models Generate Societies of Thought Authors: Junsol Kim, Shiyang Lai, Nino Scherrer, Blaise Agüera y Arcas, James Evans Institutions: University of Chicago, Google Published: January 15, 2026 (arXiv:2601.10825)
What They Tested
The researchers wanted to answer a fundamental question: why do reasoning models like DeepSeek-R1 and QwQ-32B outperform standard instruction-tuned models? The common assumption is that they simply “think longer”—generating more tokens gives them more computational runway.
But that explanation felt incomplete. The team suspected something more interesting was happening inside those long reasoning traces.
How They Tested It
The researchers analyzed 8,262 reasoning problems across multiple benchmarks, comparing reasoning models (DeepSeek-R1, QwQ-32B) against their non-reasoning counterparts (DeepSeek-V3, Qwen-2.5-32B-Instruct). They measured four types of conversational behavior in the reasoning traces: question-answering, perspective shifts, conflicts, and reconciliation. Then they went deeper, using sparse autoencoders (SAEs) to peek inside the model’s activations and identify which internal features drove reasoning performance.
Key Findings
Finding 1: Reasoning Models Talk to Themselves
The first striking result: reasoning models exhibit dramatically more conversational behavior than their instruction-tuned counterparts. DeepSeek-R1 showed 34.5% more question-answering behavior, 21.3% more perspective shifts, and 19.1% more reconciliation patterns compared to DeepSeek-V3 (all with p < 1×10⁻¹²⁵).
QwQ-32B was even more dramatic, with 45.9% more question-answering and 29.3% more conflict activation compared to Qwen-2.5-32B.
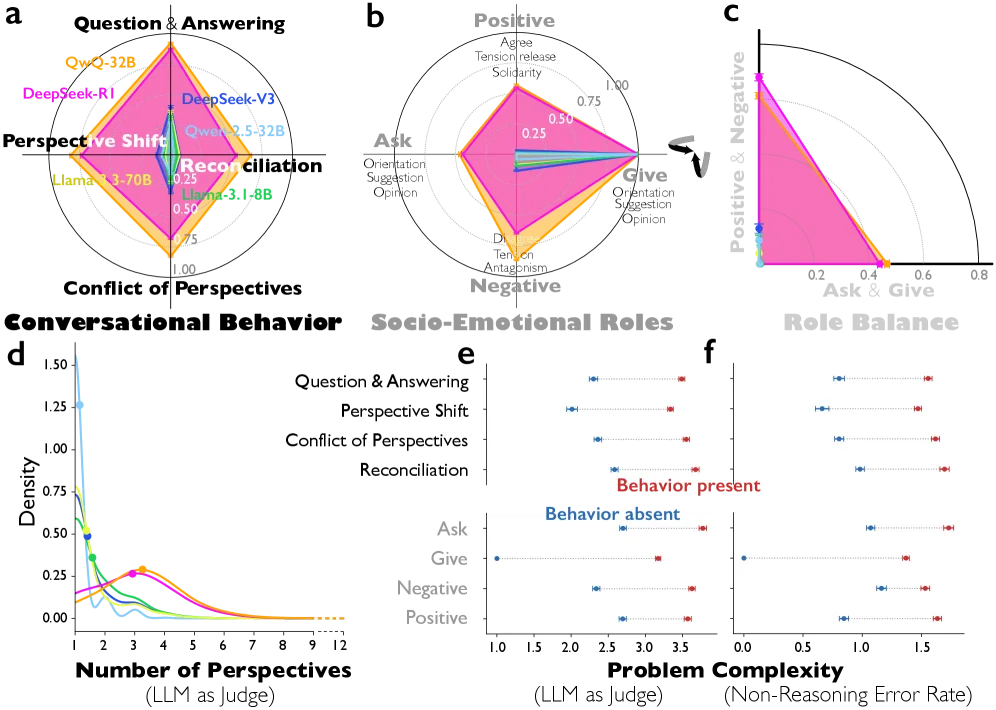 Figure 1 from Kim et al. (2026): Reasoning models (DeepSeek-R1, QwQ-32B) show dramatically higher rates of conversational behaviors compared to instruction-tuned baselines. The differences are statistically significant at p < 1×10⁻³²³.
Figure 1 from Kim et al. (2026): Reasoning models (DeepSeek-R1, QwQ-32B) show dramatically higher rates of conversational behaviors compared to instruction-tuned baselines. The differences are statistically significant at p < 1×10⁻³²³.
For marketers: When you see AI “thinking out loud” in its reasoning trace, it’s not padding—it’s literally debating with itself. That internal debate is what produces better answers.
Finding 2: Internal Diversity Predicts Performance
The researchers found that reasoning models don’t just argue more—they argue from genuinely different perspectives. Using the Big Five personality framework, they measured how much personality variation appeared across different segments of reasoning traces. DeepSeek-R1 showed 56.7% more variation in neuroticism and 29.7% more variation in agreeableness than DeepSeek-V3.
Similarly, expertise diversity—measured by embedding distance between segments—was 17.9% higher in DeepSeek-R1 and 25.0% higher in QwQ-32B compared to their non-reasoning counterparts.
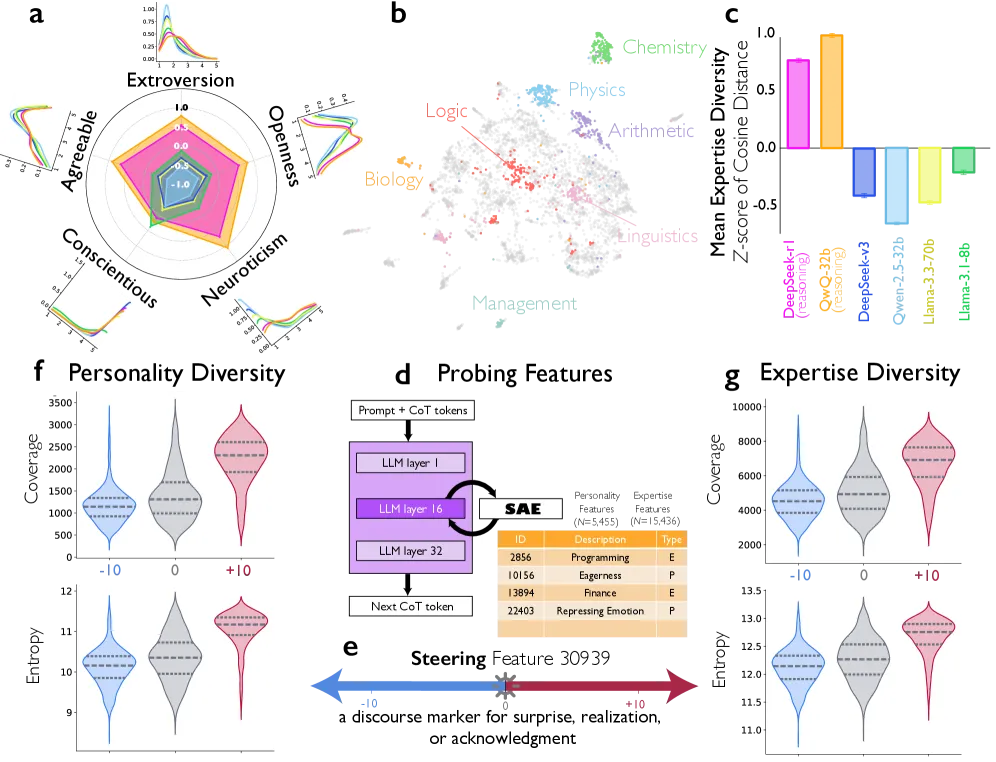 Figure 3A from Kim et al. (2026): Reasoning models show significantly higher variation in Big Five personality traits across reasoning segments, particularly in neuroticism (+56.7%) and agreeableness (+29.7%). This suggests internal “perspectives” are genuinely distinct.
Figure 3A from Kim et al. (2026): Reasoning models show significantly higher variation in Big Five personality traits across reasoning segments, particularly in neuroticism (+56.7%) and agreeableness (+29.7%). This suggests internal “perspectives” are genuinely distinct.
For marketers: The AI isn’t just generating one viewpoint and refining it. It’s generating genuinely different perspectives—a skeptic, an enthusiast, a domain expert—and letting them hash it out.
Finding 3: Conversation Features Causally Improve Reasoning
Here’s where it gets really interesting. The researchers identified a specific feature inside DeepSeek-R1 (Feature 30939) that activates during conversational moments—what they describe as “a discourse marker for surprise, realization, or acknowledgment.”
When they artificially amplified this feature during reasoning, accuracy on the Countdown task jumped from 27.1% to 54.8%—nearly doubling. This wasn’t just correlation; the causal path was clear. Amplifying conversational behavior simultaneously increased all four measured conversational patterns and improved deployment of cognitive strategies like verification (β = 5.815, p < 1×10⁻³⁴) and backtracking (β = 0.881, p < 1×10⁻⁵).
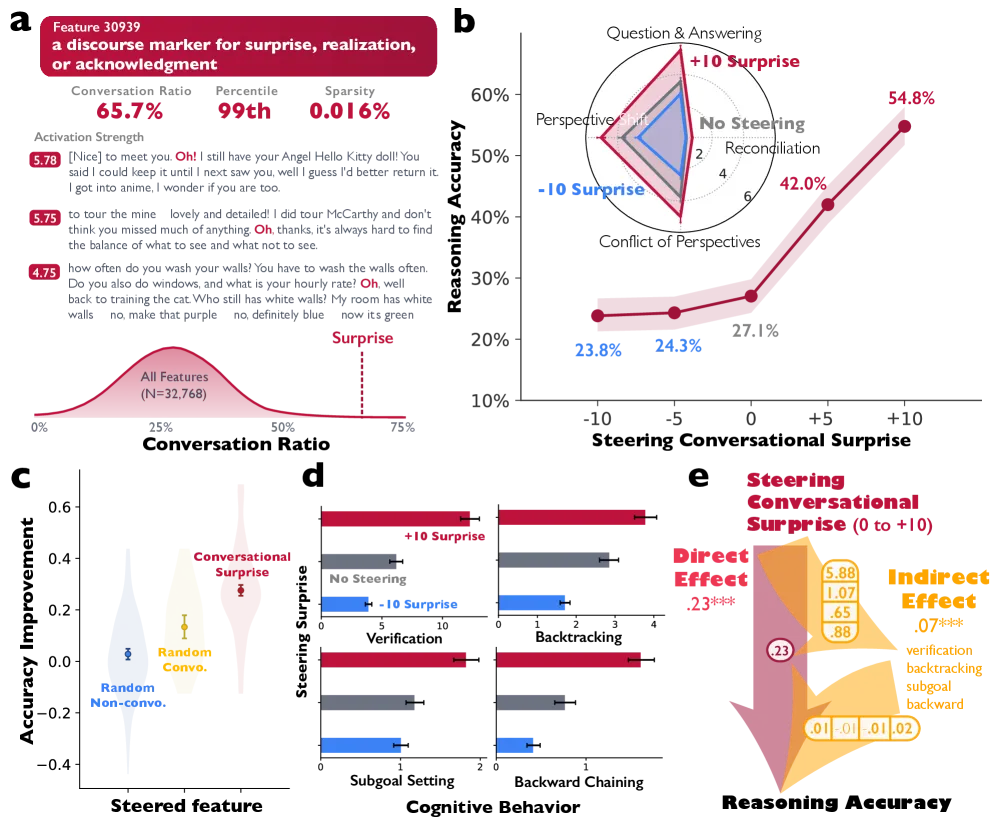 Figure 2B from Kim et al. (2026): Amplifying conversational Feature 30939 nearly doubles reasoning accuracy (27.1% → 54.8%), establishing a causal link between internal dialogue and performance.
Figure 2B from Kim et al. (2026): Amplifying conversational Feature 30939 nearly doubles reasoning accuracy (27.1% → 54.8%), establishing a causal link between internal dialogue and performance.
For marketers: You can literally make AI smarter by making it more “conversational” internally. The social dynamics aren’t a side effect—they’re the mechanism.
Finding 4: Training on Conversations Accelerates Learning
The final experiment sealed the case. Researchers fine-tuned smaller models (Qwen-2.5-3B and Llama-3.2-3B) using reinforcement learning on reasoning tasks. Some models were fine-tuned on conversational training data, others on monologue-style data.
The conversation-trained models learned faster and performed better. At training step 40, conversation fine-tuned models hit 38% accuracy versus 28% for monologue fine-tuned ones. On Llama-3.2-3B at step 150, the gap widened to 40% versus 18%—a 22 percentage point advantage.
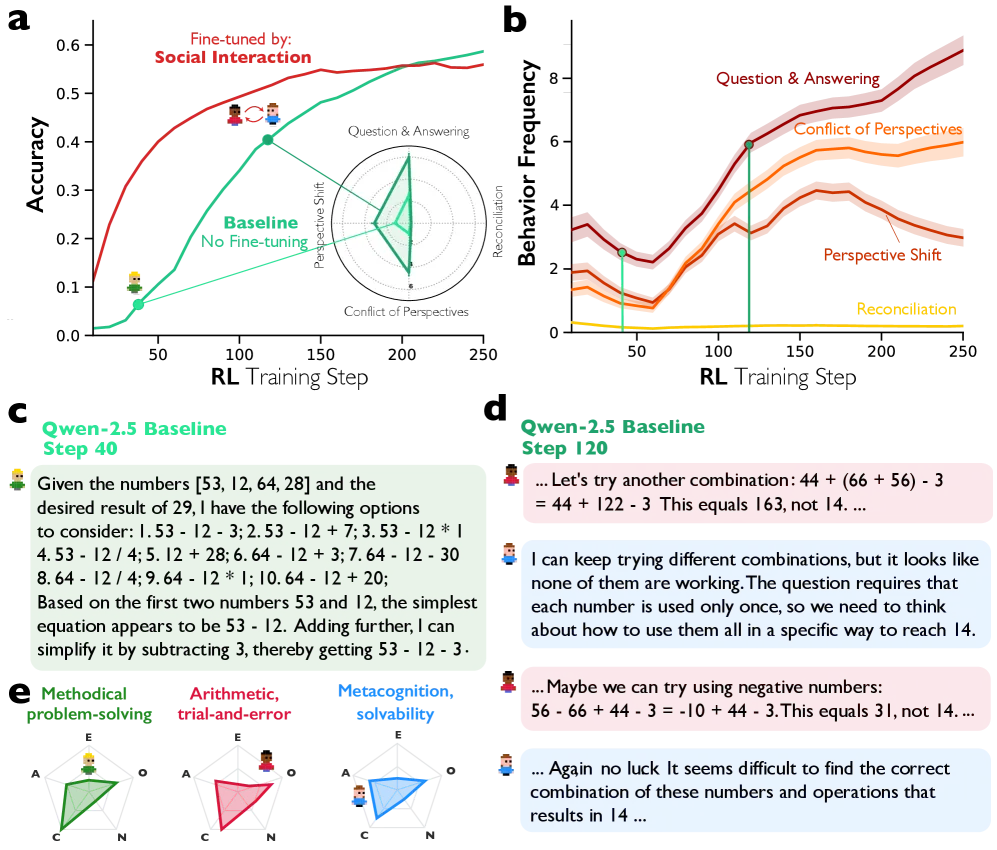 Figure 4A-B from Kim et al. (2026): Models trained on conversational data learn reasoning faster and achieve higher accuracy than those trained on monologue-style data, with gaps widening over training.
Figure 4A-B from Kim et al. (2026): Models trained on conversational data learn reasoning faster and achieve higher accuracy than those trained on monologue-style data, with gaps widening over training.
For marketers: If you’re building AI systems that need to reason well, the training data format matters enormously. Conversational structures accelerate learning.
What This Means for Content Evaluation
This research validates a core insight that informs how we think about AI-powered feedback: diverse perspectives, structured into dialogue, produce better judgments than any single viewpoint.
The paper demonstrates that even inside a single model, “diversity enables superior problem-solving when systematically structured.” The models that perform best don’t just think—they simulate something like a focus group in their reasoning traces, with different internal “participants” bringing different perspectives and expertise.
At Navay, this mirrors what we’ve built into Chorus: rather than asking one AI to evaluate your creative from one angle, we simulate panels of distinct personas that each bring different backgrounds, values, and concerns to the evaluation. The research suggests this isn’t just a nice design pattern—it’s how effective reasoning actually works at a fundamental level.
The 73% accuracy the researchers achieved in distinguishing different “speakers” within AI reasoning traces (with 82% accuracy for two speakers, declining to 69% for four) suggests these internal perspectives are genuinely distinct, not just stylistic variation. When the model generates a “skeptic” viewpoint followed by an “enthusiast” response, those represent meaningfully different computational states.
The Caveats
No research is perfect. Here’s what to keep in mind:
Model-specific findings: The detailed mechanistic analysis was conducted primarily on DeepSeek-R1-Llama-8B and smaller models. Whether the same features drive reasoning in larger models (like the full 671B DeepSeek-R1) requires further investigation.
Task domain: Most experiments used mathematical reasoning tasks (Countdown, arithmetic). The degree to which social reasoning dynamics transfer to other domains—like creative evaluation or persuasion analysis—remains an open question, though the theoretical framework suggests broad applicability.
Causality scope: While the feature steering experiments establish causality for conversational mechanisms, they don’t rule out other contributing factors to reasoning performance.
Read the Full Paper
Kim, J., Lai, S., Scherrer, N., Agüera y Arcas, B., & Evans, J. (2026). Reasoning Models Generate Societies of Thought. arXiv preprint arXiv:2601.10825.
This post is part of our Research Radar series, where we translate academic findings into marketing insights.
Sources:
Related Posts
Get diverse perspectives before you commit
Book a demo to see how Chorus gives teams structured perspectives for research and evaluation.